New Megatron-DeepSpeed with Long Sequence Support: Code and Tutorial Model Partner: Argonne National Lab

Introduction
As shown in Figure 1, GenSLMs, a 2022 ACM Gordon Bell award winning genome-scale language model from Argonne National Lab, can learn the evolutionary landscape of SARS-CoV-2 (COVID-19) genomes by adapting large language models (LLMs) for genomic data. It is designed to transform how new and emergent variants of pandemic-causing viruses, especially SARS-CoV-2, are identified and classified. GenSLM represents one of the first whole genome-scale foundation models which can generalize to other prediction tasks. A good understanding of the latent space can help GenSLMs tackle new domains beyond just viral sequences and expand their ability to model bacterial pathogens and even eukaryotic organisms, e.g., to understand things such as function, pathway membership, and evolutionary relationships. To achieve this scientific goal, GenSLMs and similar models require very long sequence support for both training and inference that is beyond generic LLMs’ long-sequence strategies like FlashAttention. Through DeepSpeed4Science’s new designs, scientists can now build and train models with significantly longer context windows, allowing them to explore relationships that were previously inaccessible.
Despite the importance of supporting very long sequence lengths and efficient training for better understanding the genome latent space in models like GenSLMs, the existing large model training frameworks such as NVIDIA Megatron-LM and old version of Megatron-DeepSpeed, and their corresponding parallelism choices do not have tailored optimizations for very long sequence training and inference. There are two main challenges with the existing frameworks. First, the existing parallelism approaches such as data, tensor, and pipeline parallelism cannot effectively address the scaling along the sequence dimension. Second, the existing large model training systems feature inferior training throughput when long sequences are required. For example, many scientists today use NVIDIA’s Megatron-LM or the older version of Megatron-DeepSpeed to train their models. Megatron-DeepSpeed is the DeepSpeed version of NVIDIA’s Megatron-LM. GenSLMs were previously trained with Megatron-DeepSpeed. However, the older version of Megatron-DeepSpeed misses many new acceleration opportunities including FlashAttention2, new fused kernels and sequence parallelism. As shown in Figure 2, the maximum sequence lengths supported by the two state-of-the-art frameworks for the 33B GenSLM model are less than 60K, which is far from the requirements of the genome-scale foundation models. And even worse, they show very poor scalability in training.

In this release, we are proud to introduce the new Megatron-DeepSpeed framework. We rebased and enabled DeepSpeed with the newest Megatron for long sequence support and other capabilities/optimizations. With the new Megatron-DeepSpeed, users can now train their large AI4Science models like GenSLMS with much longer sequences via a synergetic combination of our newly added memory optimization techniques on attention mask and position embedding, tensor parallelism, pipeline parallelism, sequence parallelism, ZeRO-style data parallelism and model state offloading.
The key properties of our new Megatron-DeepSpeed and its design/optimizations released with this blog are as follows:Enhancing Megatron-style sequence parallelism with our memory optimization techniques for attention mask and position embedding;
• Rotary positional embedding, new fused kernels, and FlashAttention v1 and v2 are also enabled;
• The overall training throughput is improved by up to 2x due to the newly enabled capability of processing larger batch sizes through the new Megatron-DeepSpeed framework;
• An average of 13x longer sequence lengths are achieved compared to the state-of-the-art training frameworks, e.g., enabling training with sequences with over a million tokens.
In the subsequent sections, we will provide a detailed discussion of rebasing efforts/achievements, new Megatron-DeepSpeed core optimizations, experimental evaluation, and comparison analysis against the existing frameworks.
Rebase and Optimizations of Megatron-DeepSpeed Framework
Megatron-DeepSpeed is a framework for training very large-scale LLMs that we have publicly released in 2022. Since its release, the research community has adopted it for training various LLMs, including the BigScience BLOOM 176B model and Argonne National Lab for GenSLMs. While containing a rich set of optimizations for training LLMs, new features and new demands are coming out rapidly such that having a stable and up-to-date support of Megatron-DeepSpeed is critical for our community of users. For example, there have been more than 1300 new commits on the Megatron-LM side and 75 new commits from the DeepSpeed side since the original Megatron-DeepSpeed release. Therefore, incorporating these new changes and ensuring the robustness of the new framework becomes a fundamental requirement for our science collaborators who use this framework extensively. In this release, we have enabled the following capabilities:
• We integrated several new features, including Megatron-style sequence parallelism, rotary positional embedding, FlashAttention v1 and v2, and new fused kernels from NVIDIA.
• We included additional optimizations specially tailored for long sequence training, such as attention map optimization and position embedding partitioning (discussed next).
• We fixed several conflicts during integration: (1) activation checkpointing where the new fine-grained partial checkpointing technique introduced by Megatron-LM was not compatible with DeepSpeed; (2) model checkpoint save/load when DeepSpeed was used with the newest Megatron-LM; and (3) major refactoring to DeepSpeed pipeline parallelism implementation for GPT models in order to work with the newest Megatron-LM.
• We fully verified the performance and correctness of GPT pretraining after the rebasing. Even though the new Megatron-DeepSpeed has tensor, sequence, and pipeline parallelism, the maximum sequence length is still inadequate. Through profiling, we identified that attention mask and weights of position encoding are main memory bottlenecks.
Further Memory Optimizations in our New Megatron-DeepSpeed
Based on the new rebase, we further enhance the Megatron-style sequence parallelism with our memory optimization techniques for attention mask and position embedding.
Memory-Efficient Generation of Attention Masks

Attention mask allows models to only attend to the previous tokens. First, the reason why the attention mask is one of the main memory bottlenecks is because of its size: [s, s], where is the sequence length, making its memory complexity as 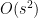

As illustrated in Figure 4, our approach involves initially determining a sequence length threshold through extensive experimentation. This threshold is identified based on achieving optimal system performance while maintaining reasonable memory usage. If the sequence length is below this threshold, we proceed to directly generate an attention mask on the GPU. However, if the sequence length exceeds this threshold, we follow a process in which we initially generate it within CPU memory, perform the necessary operations, and subsequently transfer it to GPU memory. To prevent out-of-memory errors while ensuring consistently high performance, we then establish this threshold based on the underlying GPU hardware (e.g., 16K for A100 40G GPUs).
Weights Parallelization of Position Embedding

As shown in Figure 5, position embeddings are used to identify each token’s position in the list of tokens. The size of weights of position embedding is [s, d], where s is sequence length and d is the hidden dimension; it is linearly scaled with the sequence length. In the original Megatron-LM’s design, each GPU holds a replica of these weights. Training these weights will result in the same size of gradients and m times of the optimizer states (i.e., m is determined by PyTorch). For example, the overall memory consumption is approximately 10 GB per GPU when DNA sequence lengths are longer than 100K.

As shown in Figure 6. Our method is to split weights across all GPUs when enabling sequence parallelism. Each GPU just needs to hold [s/p, d] partial weights. Thus, we reduce GPU memory consumption by p times, where p is the number of GPUs.
Algorithmic Support: Relative Position Embedding
Some users may expect a model to achieve extrapolation at inference time for sequences that are longer than it saw during training. We would use relative position embedding (e.g., attention with linear biases (or Alibi)) to let users train large language models with shorter sequences, but the trained model can infer much longer sequences. Instead of adding position embeddings to word embeddings at the bottom of the network, Alibi adds position information in the results of query-key dot product before softmax.
Evaluation
Performance Improvement of Our New Megatron-DeepSpeed Framework
In order to demonstrate the performance improvement from our new Megatron-DeepSpeed framework, we first show a range of performance comparisons between the old Megatron-DeepSpeed and the New Megatron-DeepSpeed in Table 1, when disabling ZeRO (zero_stage=0). The new Megatron-DeepSpeed is able to support much longer sequence lengths without triggering out-of-memory errors due to (1) Megatron-style sequence parallelism partitions the activation memory when sequence lengths are massive, (2) our enhanced memory optimization through memory-efficient attention mask generation and position embedding parallelization, and (3) FlashAttention V1 and V2 support, which reduces the memory consumption of the attention map calculation from quadratic to linear complexity with respect to the sequence length. The new Megatron-DeepSpeed can achieve higher TFLPOS because it includes new fused kernels from NVIDIA and supports larger batch sizes using our memory optimizations without triggering out-of-memory errors.

Max Sequence Length Capability
Through our new Megatron-DeepSpeed framework, scientists can now train their large science models like GenSLMs with much longer sequences via a synergetic combination of our newly added memory optimization techniques on attention mask and position embedding, tensor parallelism, pipeline parallelism, sequence parallelism, ZeRO-style data parallelism and model state offloading. Figure 7 and Figure 8 demonstrate that our new framework enables the longest sequence length for GenSLMs’ 25B and 33B models by up to 12X and 14X, respectively, over the previous Megatron-DeepSpeed. In terms of supported sequence lengths, this new framework also significantly outperforms NVIDIA’s Megatron-LM by up to 9.8X and 9.1X for the 25B and 33B models, respectively. For example, GenSLMs’ 25B model can now be trained with a 512K sequence of nucleotides, compared to the Argonne team’s original 42K sequence length on 64 GPUs. This drastically improves model quality and scientific discovery scope without additional accuracy loss.


Scalability Analysis
We further show the scalability of new Megatron-DeepSpeed and what different optimizations entail in Figure 9 and Figure 10. We make two observations. Firstly, when only tensor parallelism and sequence parallelism are used without position embedding optimization, the maximum length of the sequence this training system can support is about 50K, and continuing to increase GPUs will not allow the system to support longer sequences. Secondly, when enabling sequence parallelism, the maximum length of the sequence that can be supported varies within 4K.


There are several reasons behind these observations. Firstly, during training, the majority of a device’s memory is used for model state when the sequence length is small. However, as the sequence length increases, the activation memory and temporary buffers can grow significantly. For instance, GPT-style models require O(seq_length x n_layer x hidden_dim x batch_size) to store activations, and O(seq_length x seq_length) to store the attention map, and O(3 x seq_length x hidden_dim ) to train the position embedding,
Secondly, the attention map is linearly proportional to the sequence length, while the latter has quadratic memory complexity. For a 25B parameter GPT model trained with a sequence length of 100K and a batch size of 1, the activation memory requires about 12 GB and the attention map requires at least 10 GB per device, both of which are non-trivial. By using techniques such as model parallelism, we can reduce the memory footprint by using aggregated device memory for activation memory from 480 GB to 12 GB. Finally, we also optimized the attention map’s memory usage by avoiding allocating temporary buffers on the device, which reduces the peak memory consumption from 54 GB (Out of Memory) to 39 GB. Even if we only use casual flash attention (avoid generating attention map explicitly), the memory requirement for training position embedding is linearly scaled with sequence length, and the needed memory is over 10 GB when a sequence length is over 100K.
Case Study: GenSLMs
Please visit here to find out how the new Megatron-DeepSpeed helps genome scientists at Argonne National Lab by enhancing their capability to do bigger and better science !
Release: Try the New Megatron-DeepSpeed Today!
We are very excited to share that the new Megatron-DeepSpeed is now open-sourced and available to our deepspeed user community.
• To get started, please visit our https://www.deepspeed.ai/deepspeed4science/ for the new Megatron-DeepSpeed capabilities including long sequence support.
• We will continue to improve Megatron-DeepSpeed with your feedback and support.
DeepSpeed welcomes your contributions! We encourage you to report issues, contribute PRs, and join discussions on the Megatron-DeepSpeed GitHub page. Please see our contributing guide for more details. For requests, please directly email to deepspeed-info@microsoft.com.